



















Aujourd’hui, une majorité utilise des applications comme Tik Tok, Facebook, Google Maps ou encore Instagram. En l’occurrence, elles génèrent des exaoctets de données par jour et par personne. En multipliant ce phénomène par plusieurs milliards d’utilisateurs dans le monde, on comprend facilement le nombre exponentiel de données générées chaque instant.
Ces données sont justement générées, traitées et analysées grâce à ce qu’on appelle le Big Data. Dans cet article, nous verrons ensemble les caractéristiques de ce phénomène, les défis et opportunités qu’il représente.
Qu’est ce que le Big Data ?
Le Big Data est un terme qui désigne la masse des données qui transitent en permanence sur le web.
Chaque jour, nous générons environ 2,5 trillions d’octets de données, provenant de diverses sources (messages envoyés, vidéos publiées, signaux GPS, horaires de train, affiches de film…).
Cet ensemble de données est si volumineux qu’il dépasse les capacités des outils de gestion de base de données traditionnels.
C’est pourquoi, il est aujourd’hui nécessaire de créer des algorithmes très complexes pour pouvoir les traiter. Grâce à eux, un hôtel peut par exemple prévoir son taux de remplissage en fonction du nombre de billets vendus sur les sites de compagnies aériennes.
Dans un autre registre, la production d’un film est capable de prévoir combien d’entrées le long-métrage fera en fonction des likes que génère la bande annonce. C’est également ce à quoi sert le Big Data.
Il collecte, stocke et analyse en quantité massive ces données afin d’en extraire des informations précieuses et exploitables. Elles représentent une grande valeur ajoutée pour les entreprises, qui peuvent en déduire des informations clés. Et ainsi, prendre des décisions éclairées. Leurs performances en sont drastiquement améliorées.
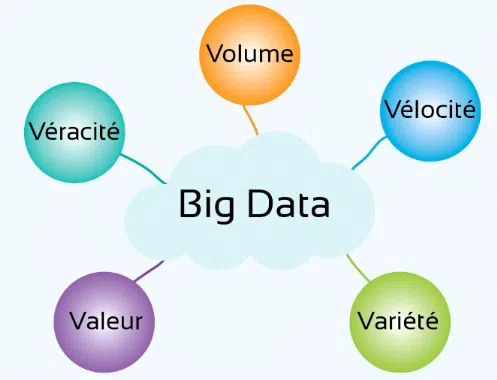
Les 5 V du Big Data
Parce que le Big Data est difficile à définir, la méthode des 5V propose une description de ce phénomène par ses caractéristiques principales.
En cela, on trouve : le Volume des données, leur diversité (Variété), leur vitesse de génération et de traitement (Vélocité), leur changement constant (Variabilité) ainsi que leur potentiel à apporter des bénéfices (Valeur).
Volume
Le volume se réfère à la quantité massive de données, qui proviennent de nombreuses sources. Avec le Big Data, de gros volumes de données sont analysés chaque jour.
Il peut s’agir de données provenant de type texte (mails, sms…), de l’audio (podcasts, échanges en visioconférence), de la vidéo, de l’image, de la photo… Cela peut également prendre la forme de clics, likes ou encore de partages.
Dans ce contexte, les entreprises font face à des quantités différentes de données. Pour certaines entreprises, cela peut correspondre à des dizaines de téraoctets de données. Pour d’autres, il peut s’agir de centaines de pétaoctets.
Variété
La variété fait allusion aux nombreux types de données disponibles. On en trouve trois principales :
- Les données structurées : ce sont des données préalablement formatées selon une structure donnée avant d’être placées dans un système de stockage. Les adresses, numéros de carte de crédit ainsi que la géolocalisation sont des exemples de données structurées.
- Les données semi-structurées : qui ne sont pas capturées ou formatées de manière conventionnelle. Les e-mails en sont un exemple.
- Les données non structurées : comme les vidéos, audios et images, qui sont des données stockées dans leur format d’origine.
Cette grande variété de données est d’autant plus importante que les sources sont tout autant diversifiées. Elles ont en revanche pour point commun d’être toutes digitales.
Parmi les principales sources, on compte les réseaux sociaux, les objets connectés, les sites web et cookies, les données transactionnelles d’achat sur internet…
Vélocité
Il s’agit de la vitesse à laquelle les données sont générées, collectées et traitées. Jusqu’il y a quelques années, traiter les bonnes données et faire remonter les bonnes informations prenait beaucoup de temps.
Aujourd’hui, les données sont disponibles en temps réel. Si cette vélocité bénéficie à tous les secteurs, elle montre sa plus-value dans les secteurs où la disponibilité de l’information en temps réel est nécessaire.
C’est le cas du secteur de la santé par exemple. Il y existe aujourd’hui de nombreux dispositifs médicaux qui surveillent les patients et collectent des données en temps réel. Cela permet notamment un meilleur suivi des malades.
Véracité
Ce V fait référence à la qualité et de l’exactitude des données. Autrement dit, c’est le niveau de confiance les dirigeants d’entreprise donnent aux informations générées.
En effet, les données possèdent une valeur intrinsèque. Mais cela ne sert à rien tant que cette valeur n’est pas découverte ni vérifiée. C’est justement ce à quoi sert le Big Data. Parce que beaucoup d’entreprises fondent leurs décisions commerciales/stratégiques sur ces données, il est crucial d’être sûr de leur exactitude.
Or, cette authenticité peut être rapidement un obstacle. Du fait de la rapidité des échanges de données, elles peuvent devenir facilement obsolètes.
Par ailleurs, de nombreuses informations qui sont partagées via l’Internet et les réseaux sociaux ne sont pas forcément correctes. C’est notamment le problème des « fake news », qui peuvent avoir des conséquences économiques et politiques désastreuses. La véracité des données est ainsi un enjeu crucial pour le Big Data.
Valeur
Toutes les données n’ont pas la même valeur. Or, c’est l’un des aspects les plus importants du Big Data. Ce concept se réfère à la valeur ajoutée que les données apportent aux entreprises.
Autrement dit, la valeur des données se traduit par la plus-value qu’elles génèrent dans les entreprises. Elles les utilisent notamment pour éclairer leurs décisions. Cela peut se traduire alors par une plus grande efficacité opérationnelle, de meilleures relations avec les clients, le développement de nouveaux avantages commerciaux…
Big data et intelligence artificielle : un lien étroit commun
Le Big Data et l’intelligence artificielle (IA) sont deux domaines technologiques en constante évolution qui sont étroitement liés.
D’un côté, le Big Data fournit les données massives nécessaires à l’IA pour apprendre, s’améliorer et prendre des décisions intelligentes. Autrement dit, les données sont le « carburant » de l’IA. Plus elle a de données pertinentes à traiter, plus elle peut fournir des résultats précis et fiables.
D’un autre, l’IA est un outil puissant qui extrait des informations à forte valeur ajoutée, à partir du Big Data. En effet, l’IA fournit des informations précieuses pour les entreprises en identifiant par exemple des tendances, des modèles et des corrélations cachées.
Elle peut également fournir des recommandations et des prédictions précises à partir des données. Les entreprises peuvent alors plus facilement prendre des décisions éclairées et ainsi améliorer leurs performances.
Ensemble, le Big Data et l’IA aident alors les entreprises à tirer parti du plein potentiel des données.
Les technologies d’intelligence artificielle utilisées dans le Big Data
Il existe plusieurs technologies d’intelligence artificielle (IA) utilisées dans le Big Data. Elles servent notamment à analyser et extraire des informations utiles à partir de grands ensembles de données. Parmi les principales, on compte :
L’apprentissage automatique (Machine Learning)
C’est une technologie d’IA qui permet aux ordinateurs d’apprendre à partir de données, sans avoir été explicitement programmés.
Il a pour objectif de transmettre un apprentissage à un ordinateur. L’apprentissage concerne généralement une application bien précise et peut se faire sans la supervision de l’Homme.
Il est largement utilisé dans le Big Data pour identifier des modèles, des tendances et corrélations cachées dans les données. Pour ce faire, la technologie est programmée à l’aide d’algorithmes.
Elle ingère une quantité de données massive et de statistiques. A partir de ces données, elle va pouvoir déduire des modèles (patterns) et s’entraîner. Avec le temps, la technologie réalisera des analyses prédictives de plus en plus précises dans l’objectif de résoudre des problèmes complexes en un minimum de temps.
Le traitement du langage naturel (NLP)
Le traitement du langage naturel (NLP) est une autre technologie d’IA utilisée dans le big data pour analyser et comprendre le langage humain.
On l’utilise pour extraire des informations utiles à partir de grandes quantités de données textuelles, telles que les commentaires des clients, les avis sur les produits et les publications sur les réseaux sociaux.
Ainsi, cela permet aux entreprises de mieux comprendre le sentiment général sur les médias sociaux et conversations avec les clients.

La reconnaissance d’images
Comme son nom l’indique, ce type de technologie permet aux ordinateurs d’identifier et de comprendre les images et les vidéos.
Grâce à des algorithmes entraînés, elle sait reconnaître, traiter et analyser une donnée visuelle. Au même titre qu’un humain, elle est par exemple capable de faire la différence entre divers objets ou couleurs.
L’IA identifie alors des éléments de reconnaissance et les recoupe afin d’identifier l’élément présenté. Ainsi, l’Intelligence Artificielle peut classifier des images en fonction de ce qu’elles représentent.
Dans le cadre du Big Data, elle permet d’analyser de grandes variétés d’images et de vidéos, telles que les images satellites, les vidéos de surveillance et les images médicales. C’est par exemple ce qu’utilise Facebook en créant de courtes vidéos qui regroupent d’anciennes photos.
Grâce à la reconnaissance d’image, le réseau social est alors capable de faire des vidéos « à thème » et sélectionner habilement les photos qui s’y présentent. En cela, Facebook offre de meilleurs services à chaque fois à chaque nouvelle connexion.
L’analyse prédictive
L’analyse prédictive consiste à utiliser des données historiques pour prédire les tendances et les comportements futurs.
Elle permet notamment de prévoir les ventes, les tendances du marché et les comportements des clients, à partir de données historiques stockées. Cette technologie sert également à prévoir et évaluer des risques. Les prises de décisions des entreprises sont plus éclairées pour mener les bonnes actions auprès des bonnes personnes, au bon moment.
Les réseaux de neurones
Ce type de technologie IA est comme un cerveau humain. En effet, en appliquant des techniques d’apprentissage profond, cette technologie est capable de reconnaître les modèles et tirer des conclusions sans intervention humaine.
Au fil du temps, elle affine de mieux en mieux les résultats. Les réseaux de neurones sont également capables d’apprendre de leurs erreurs et trouver en pure autonomie des raccourcis très utiles dans l’analyse du Big Data.
Parce qu’ils sont conçus pour apprendre à partir de données, ils sont particulièrement adaptés à l’analyse de données Big Data.
Plus avancée que d’autres, cette technologie permet alors de résoudre des problèmes plus complexes, tels que la reconnaissance vocale, la reconnaissance d’images et l’analyse prédictive.
Big Data et IA : les entreprises ont tout intérêt à en tirer profit
À l’heure actuelle, le Big Data revêt une importance capitale pour les entreprises. En effet, s’il est bien utilisé, il peut représenter un nombre incalculable d’avantages.
Prenez par exemple les plus grandes entreprises de technologie du monde. Une grande partie de la valeur qu’elles offrent provient de leurs données qu’elles analysent en permanence pour accroître leur efficacité et développer de nouveaux produits.
Avec le big data, les entreprises sont à même de prendre les décisions les plus adéquates en un rien de temps. Leur travail est simplifié, et surtout, plus rentable.
Grâce à l’extrême variété des données mises à disposition, le Big Data permet alors aux entreprises une meilleure efficacité opérationnelle, une plus grande personnalisation de l’expérience client, de meilleures innovations…
En cela, le Big Data se montre comme un vrai partenaire dans la prise de décision stratégiques et commerciales. Elles voient alors leur compétitivité et agilité renforcées sur un marché qui est toujours plus concurrentiel.
Par ailleurs, les avancées technologiques récentes ont réduit de manière exponentielle le coût de stockage et de calcul des données. Ce qui facilite plus que jamais leur stockage. Un plus grand volume de Big Data étant maintenant plus économique et accessible, les entreprises sont alors en mesure de prendre des décisions commerciales plus précises.
Intelligence artificielle et Big Data : les défis majeurs
Si le Big Data et l’IA présentent de nombreux avantages, on leur associe également des défis importants. Voici quelques-uns des défis les plus courants liés à leur utilisation.
Qualité des données
Les données doivent être précises, complètes, cohérentes et fiables pour être utiles. Au contraire, celles qui sont erronées ou incomplètes peuvent conduire à des résultats inexacts. Et donc à une prise de décision défaillante.
Cela peut représenter un coût considérable et une perte de temps que les entreprises auraient pu facilement éviter en les vérifiant dès le début. C’est pourquoi de plus en plus d’entreprises se dotent d’un plan complet afin d’assurer une qualité aux données, de leur réception à leur traitement, voire leur fin de vie.
Sécurité des données
Si la qualité des données est importante, leur sécurité est cruciale. A titre indicatif, on estime qu’une attaque de ransomware se produit toutes les dix secondes dans le monde. Ainsi, l’enjeu de la sécurité des données est au cœur des problématiques des entreprises.
C’est pourquoi il est crucial que chaque entreprise prenne toutes les mesures nécessaires pour prévenir la corruption des données. On compte notamment l’utilisation de systèmes, processus et procédures qui rendent les données inaccessibles aux individus susceptibles de les utiliser de manière nuisible. Ainsi, les données des clients et employés se voient protégées.
Complexité technique
Le Big Data est une mine d’or d’informations, à condition de savoir les traiter, analyser et stocker ! La complexité technique est directement liée aux 5V du Big Data.
Du fait du grand volume, de la diversité et rapidité de ces données, elles représentent une grande complexité quant à leur bonne utilisation. Parce que l’analyse du Big Data demande des compétences particulières, une entreprise doit disposer d’un data scientist ou data analyst afin de se donner les moyens de réussir.
Éthique et confidentialité
L’utilisation du Big Data et de l’intelligence artificielle soulève un certain nombre de préoccupations éthiques et de confidentialité. Que ces risques soient politiques, économiques, sociaux ou encore environnementaux, le Big Data a montré plus d’une fois ses dérives.
Prenez par exemple le scandale Cambridge Analytica, un cabinet de conseil qu’on accuse d’avoir utilisé les données personnelles de 87 millions d’utilisateurs de Facebook à leur insu, dans le cadre de la campagne présidentielle américaine de 2016.
Pour contrer cela, de nombreuses réformes et législations ont été mises en place afin d’encadrer les dérives du Big Data, en Europe (RGPD) comme aux Etats-Unis (CCPA).
Coût
Enfin, le Big Data peut être coûteux. En effet, l’utilisation de technologies de pointe pour collecter, stocker, traiter et analyser de grandes quantités de données peut s’avérer onéreuse.
Un autre élément que les entreprises doivent prendre en considération dans l’équation : les coûts indirects. Ils se réfèrent notamment aux coûts d’opportunité liés à l’allocation de ressources à des projets Big Data plutôt qu’à d’autres.
Dans ce cadre, les entreprises doivent évaluer les coûts au regard des avantages de l’utilisation du Big Data et de l’IA pour déterminer si cela en vaut la peine, ou non.