Le succès d’une plateforme web se mesure souvent à sa croissance : augmentation du trafic, accumulation de données utilisateurs et complexification des fonctionnalités. Paradoxalement, c’est précisément ce succès qui devient le talon d’Achille de nombreuses entreprises. Chez La Fabrique du Net, nous sommes témoins chaque semaine de projets digitaux qui s’effondrent sous leur propre poids, victimes de ce que l’on appelle la dette technique ou d’une architecture initialement mal dimensionnée. Un site qui ralentit, des temps de chargement qui explosent lors des pics d’affluence ou une impossibilité d’ajouter de nouvelles fonctionnalités sans casser l’existant sont des symptômes classiques d’un manque d’anticipation.
La pérennité et la scalabilité (ou mise à l’échelle) ne sont pas des luxes réservés aux géants de la tech. Ce sont des impératifs stratégiques pour toute PME ou ETI ambitionnant de croître. Concevoir une architecture web capable d’absorber la charge future sans nécessiter une refonte totale tous les deux ans est un défi majeur. Notre position d’observateur privilégié, facilitant la mise en relation entre porteurs de projets et agences web, nous permet d’identifier les stratégies techniques gagnantes et celles qui mènent à l’impasse. À travers cet article, nous détaillons huit piliers fondamentaux pour bâtir une infrastructure web robuste, durable et évolutive.

L’architecture logicielle : Du monolithe modulaire aux microservices
Le choix de l’architecture logicielle initiale est sans doute la décision la plus lourde de conséquences pour la scalabilité future d’une application web. Pendant longtemps, le débat s’est résumé à une opposition binaire entre une architecture monolithique et une architecture en microservices. La réalité du terrain, telle que nous l’observons sur les centaines de projets techniques qui transitent par notre plateforme, est beaucoup plus nuancée. Une architecture mal adaptée au stade de développement de l’entreprise peut freiner l’innovation ou, à l’inverse, exploser les coûts de maintenance.
Le monolithe modulaire comme socle de départ
Contrairement aux idées reçues, démarrer par une architecture monolithique n’est pas une erreur, à condition qu’elle soit bien conçue. Pour l’immense majorité des projets en phase de lancement ou de croissance initiale, le monolithe reste la solution la plus pragmatique. Il permet un développement rapide, un déploiement simplifié et une gestion des transactions facilitée. Cependant, la clé de la pérennité réside dans la modularité. Un « monolithe modulaire » sépare logiquement le code en domaines métiers distincts (par exemple : gestion des utilisateurs, catalogue produit, facturation) au sein d’une même base de code. Cette rigueur permet, le jour où la charge devient critique sur un module précis, de l’extraire pour en faire un service indépendant sans avoir à réécrire l’ensemble de l’application.
La transition vers les microservices
Le passage aux microservices ne doit se faire que lorsque des contraintes spécifiques l’imposent. Nous observons souvent des entreprises qui adoptent cette architecture trop tôt, subissant alors une complexité opérationnelle ingérable (orchestration, latence réseau, cohérence des données). Les microservices deviennent pertinents lorsque l’équipe technique dépasse une certaine taille (généralement plus de 15 ou 20 développeurs) ou lorsque des parties de l’application nécessitent des technologies hétérogènes ou des cycles de déploiement très différents. Par exemple, un moteur de recherche interne très sollicité peut être isolé pour bénéficier de ressources serveurs dédiées, tandis que le blog institutionnel reste sur une infrastructure standard. Cette transition doit être progressive et pilotée par les métriques de performance.
Stratégies de bases de données et persistance des données
La base de données est traditionnellement le goulot d’étranglement numéro un des applications web à fort trafic. Contrairement aux serveurs d’application qui peuvent être multipliés assez aisément, la gestion de l’état (la donnée) est complexe à mettre à l’échelle. Une grande partie des problèmes de performance lors des pics de charge provient de requêtes SQL mal optimisées ou d’une structure de base de données inadaptée au volume.
Optimisation et indexation
Avant même de penser à des architectures complexes, la pérennité passe par l’hygiène du code SQL. L’absence d’index sur des colonnes fréquemment interrogées oblige le moteur de base de données à parcourir l’intégralité des tables, ce qui est imperceptible avec 1 000 entrées mais catastrophique avec 1 million. L’utilisation d’outils d’analyse de requêtes (comme EXPLAIN en SQL) doit être systématique. De plus, la dénormalisation, bien que contraire aux principes académiques, est souvent une stratégie nécessaire pour la lecture à haute fréquence, évitant des jointures coûteuses en ressources.
Réplication et Sharding
Pour assurer la scalabilité, deux techniques majeures s’imposent. La réplication Maître-Esclave permet de séparer les opérations d’écriture (sur le maître) des opérations de lecture (réparties sur plusieurs esclaves). Cela soulage considérablement la base principale, sachant que la majorité des applications web effectuent beaucoup plus de lectures que d’écritures. Lorsque cela ne suffit plus, le « Sharding » (fragmentation horizontale) consiste à découper la base de données en plusieurs morceaux répartis sur différents serveurs. Par exemple, les données des utilisateurs européens sur un serveur, celles des américains sur un autre. Cette approche est complexe à mettre en œuvre et doit être anticipée dans la conception du schéma de données, mais elle offre une scalabilité quasi illimitée.
La gestion du cache : Accélérateur de performance
Le moyen le plus efficace de scaler une application est de ne pas solliciter le serveur d’application ou la base de données du tout. C’est ici qu’intervient la stratégie de mise en cache. Chez La Fabrique du Net, nous recommandons systématiquement une stratégie de cache à plusieurs niveaux. Un site sans cache est un site qui recalculera la même page d’accueil pour mille visiteurs simultanés, ce qui est un gaspillage de ressources colossal.
Cache applicatif et d’objets
Au niveau du code, l’utilisation de solutions de stockage en mémoire comme Redis ou Memcached est indispensable pour stocker les résultats de requêtes lourdes ou de calculs complexes. Si la génération d’un menu complexe prend 200 millisecondes, le stocker en cache permet de le servir en moins de 2 millisecondes aux utilisateurs suivants. La difficulté technique réside ici dans l’invalidation du cache : savoir précisément quand supprimer une donnée stockée parce qu’elle a été mise à jour en base. Une mauvaise gestion de l’invalidation entraîne l’affichage de données obsolètes, ce qui peut être critique pour un site e-commerce (prix, stock).
Cache HTTP et CDN
Notre propre expérience : lafabriquedunet.fr, près de 10 000 pages publiées, tourne sur une architecture volontairement restée au deuxième palier : monolithe Laravel exécuté sous Octane, cache d’objets Redis, et CDN Cloudflare avec mise en cache du HTML et purge ciblée à chaque édition de contenu. Deux leçons tirées de l’exploitation au quotidien : le cache HTML ne vaut que si les purges sont chirurgicales (purger tout le site à chaque modification annule le bénéfice), et chaque nouvelle fonctionnalité de filtrage ou de personnalisation doit être conçue pour préserver la cacheabilité des pages, sinon c’est toute la stratégie qui s’effondre silencieusement.
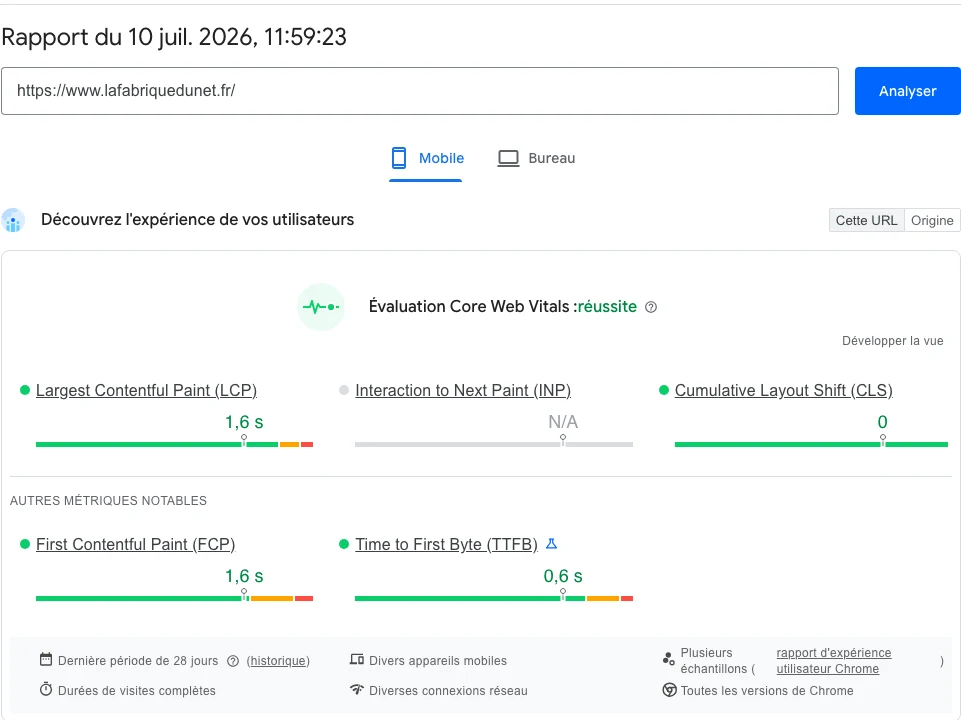
Le second niveau se situe en amont du serveur, via des reverse proxies comme Varnish ou Nginx, et des réseaux de distribution de contenu (CDN). Ces outils stockent des versions statiques des pages ou des ressources (images, CSS, JS) et les servent directement à l’utilisateur depuis un serveur géographiquement proche de lui. Pour une application à portée internationale, un CDN est non-négociable. Il réduit la latence réseau et protège le serveur d’origine contre les pics de trafic soudains. Une mise en cache HTTP bien configurée peut absorber l’essentiel du trafic entrant sans que les serveurs d’application ne soient sollicités.
Infrastructure Cloud et Auto-scaling
L’époque où l’on louait des serveurs physiques dédiés avec une capacité fixe est révolue pour les projets ambitieux. L’infrastructure Cloud (AWS, Google Cloud, Azure) offre une élasticité indispensable à la scalabilité. Cependant, « aller sur le cloud » ne suffit pas ; il faut concevoir l’application pour qu’elle soit « Cloud Native ».
Conteneurisation et Orchestration
La pérennité passe par la standardisation des environnements. L’utilisation de conteneurs (Docker) garantit que le code s’exécute exactement de la même manière sur le poste du développeur, en pré-production et en production. Pour la scalabilité, l’orchestration de ces conteneurs via Kubernetes est devenue le standard de l’industrie, bien que complexe. Elle permet de gérer le cycle de vie des applications, leur déploiement sans interruption de service et leur mise à l’échelle automatique.
Auto-scaling horizontal
L’avantage majeur du Cloud est l’auto-scaling. Contrairement au scaling vertical (ajouter plus de RAM ou de CPU à une machine), qui a des limites physiques et nécessite souvent un redémarrage, le scaling horizontal consiste à ajouter des instances de serveurs (des nœuds) automatiquement lorsque la charge augmente. Si le CPU moyen de votre flotte de serveurs dépasse 70 %, le système démarre automatiquement deux nouveaux serveurs pour répartir la charge. Une fois le pic passé, ces serveurs sont éteints pour optimiser les coûts. Cette élasticité est la seule réponse viable économiquement aux variations de trafic imprévisibles.
Découplage Frontend et Backend (Headless)
Les architectures traditionnelles couplaient fortement l’interface utilisateur (Frontend) et la logique métier (Backend). Aujourd’hui, pour garantir une évolution indépendante des deux parties, le découplage est une stratégie de pérennisation majeure. C’est l’avènement des architectures Headless.
L’approche API-First
En concevant le Backend comme une simple API (REST ou GraphQL) qui délivre des données brutes (JSON), on rend le cœur du système agnostique de l’interface. Cela signifie que la même logique métier peut alimenter un site web, une application mobile, une borne interactive ou une montre connectée. Pour une entreprise, cela sécurise l’investissement backend sur le long terme : si demain une nouvelle technologie d’interface apparaît, il suffira de développer un nouveau frontend sans toucher au cœur du système.
Technologies Frontend modernes
Côté Frontend, l’utilisation de frameworks comme React, Vue.js ou Angular, souvent combinés à des générateurs de sites statiques (Jamstack), permet de déporter une grande partie de la logique d’affichage dans le navigateur du client. Cela allège considérablement la charge des serveurs. De plus, ces technologies facilitent la création de Progressive Web Apps (PWA), offrant une expérience proche du natif et une meilleure résistance aux réseaux instables, un atout pour l’expérience utilisateur et donc la pérennité de l’audience.
Qualité du code et Dette technique
La scalabilité n’est pas qu’une question d’infrastructure, c’est aussi une question de maintenabilité du code. Une base de code « sale », sans tests et mal documentée, devient rapidement impossible à faire évoluer. La vitesse de développement chute, et chaque nouvelle fonctionnalité introduit des bugs (régressions).
Intégration et Déploiement Continus (CI/CD)
L’automatisation est le gardien de la qualité. La mise en place de pipelines CI/CD assure que chaque modification du code est automatiquement testée, validée et déployée. Cela réduit le risque d’erreur humaine et permet des cycles de déploiement très courts. Une entreprise capable de déployer des correctifs ou des améliorations plusieurs fois par jour est infiniment plus résiliente qu’une entreprise qui déploie une fois par mois avec la peur au ventre.
Tests automatisés et Refactoring
Un code pérenne est un code testé. Les tests unitaires, d’intégration et de bout en bout (E2E) agissent comme un filet de sécurité permettant aux développeurs de refactoriser (améliorer) le code sans crainte de casser des fonctionnalités existantes. Chez La Fabrique du Net, nous conseillons d’allouer systématiquement 15 à 20 % du budget de développement à la réduction de la dette technique et à l’écriture de tests. C’est un investissement qui se rentabilise dès la deuxième année d’exploitation.
Sécurité et Conformité à l’échelle
À mesure qu’un site grandit, il devient une cible plus attractive pour les attaques. La sécurité ne peut pas être une « surcouche » ajoutée à la fin ; elle doit être intégrée dès la conception (Security by Design). Une faille de sécurité majeure peut anéantir la réputation d’une entreprise et stopper net sa croissance.
Protection contre les attaques volumétriques
La scalabilité doit inclure la capacité à absorber des attaques DDoS (déni de service). L’architecture doit prévoir des pare-feux applicatifs (WAF) capables de filtrer le trafic malveillant avant qu’il n’atteigne les serveurs d’application. La limitation de débit (Rate Limiting) au niveau des API est également cruciale pour empêcher un utilisateur ou un bot de saturer le système avec des milliers de requêtes.
Gestion des données et RGPD
La pérennité implique aussi la conformité légale. Avec l’accumulation de données, le respect du RGPD devient un défi technique. L’architecture doit permettre l’anonymisation, la portabilité et la suppression des données utilisateurs de manière efficace. Une base de données mal structurée rendra le droit à l’oubli techniquement complexe et coûteux à mettre en œuvre manuellement.
Observabilité et Monitoring proactif
On ne peut pas améliorer ce que l’on ne mesure pas. Une architecture scalable est une architecture « observable ». Il ne s’agit pas seulement de savoir si le serveur est allumé (monitoring classique), mais de comprendre comment le système se comporte de l’intérieur.
Centralisation des logs et APM
Dans une architecture distribuée (cloud, microservices), les logs sont éparpillés sur des dizaines de machines. Il est impératif d’utiliser des outils de centralisation (type ELK Stack ou Datadog) pour corréler les événements. Les outils d’APM (Application Performance Monitoring) permettent de tracer une requête à travers tout le système pour identifier précisément quelle fonction ou quelle requête SQL ralentit l’ensemble. Cette visibilité permet d’agir proactivement avant que l’utilisateur ne ressente une dégradation.
Scénario type : moderniser sans tout casser
Pour illustrer concrètement l’enchaînement de ces choix architecturaux, voici un scénario type de refonte progressive, représentatif des projets e-commerce à fort trafic. Les détails sont illustratifs.
Le point de départ : un e-commerçant établi, dont la boutique vieillissante tourne sur un serveur dédié unique. Chaque campagne d’emailing ou période de soldes entraîne des ralentissements sévères, voire des erreurs 503 ; les temps de chargement s’envolent en période de pointe, et la base de données monolithique bloque l’intégration avec le nouvel ERP.
La démarche : plutôt qu’une refonte totale risquée, une stratégie de découplage progressif (headless). Le frontend est reconstruit avec un framework moderne pour un affichage rapide, et communique par API avec le backend existant, migré ensuite brique par brique vers le cloud. Une couche de cache Redis est déployée sur le catalogue, et la recherche est déportée sur un moteur dédié type Elasticsearch.
Ce que ce scénario illustre : la modernisation réussie n’est pas un big bang mais une suite d’étapes sécurisées, où chaque brique (cache, recherche, frontend, cloud) soulage le système existant sans interrompre l’activité. C’est exactement ce qu’il faut exiger d’un prestataire : un plan de transition, pas une promesse de refonte miracle.
Et en vrai ? Parmi les réalisations publiées avec leur budget par les agences référencées sur notre plateforme, un projet à 2 000 000 € sur 12 mois illustre ce scénario à grande échelle : la refonte intégrale d’une plateforme nationale d’instruction de dossiers de financement, avec migration complète vers de nouvelles infrastructures serveurs sans interruption de service. Résultats annoncés par l’agence : disponibilité supérieure à 99 %, volume de demandes traitées doublé en un an à équipe constante, et 50 000 dossiers actifs gérés simultanément. La continuité de service pendant la migration, c’est précisément ce que permet la refonte progressive décrite ci-dessus.
Les erreurs les plus fréquentes
Au travers des audits que nous recevons, certaines erreurs de conception reviennent systématiquement et compromettent la pérennité des projets web.
L’optimisation prématurée
C’est sans doute l’erreur la plus coûteuse. Vouloir implémenter une architecture microservices complexe type « Netflix » pour une startup qui n’a pas encore 1 000 utilisateurs est un non-sens. Cela consomme le budget, retarde le lancement et crée une complexité inutile. Il faut construire pour les besoins actuels en prévoyant l’évolution, pas construire pour des besoins hypothétiques dans 5 ans.
Négliger les assets statiques
Nous voyons encore trop de sites servir des images de 4 Mo ou des fichiers JavaScript non minifiés directement depuis leur serveur web principal. Cela sature la bande passante inutilement. L’absence de compression et de redimensionnement automatique des images est une cause majeure de lenteur qui ne se résout pas en ajoutant des serveurs plus puissants.
Le couplage temporel
Concevoir des processus qui doivent s’exécuter de manière synchrone est une erreur critique pour la scalabilité. Par exemple, si l’envoi d’un email de confirmation de commande se fait dans la même transaction que le paiement, et que le serveur d’email ne répond pas, la commande échoue. Il est crucial d’utiliser des files d’attente (queues) pour traiter ces tâches de manière asynchrone (en arrière-plan).
Comment bien choisir son agence pour une architecture scalable
Sélectionner le bon partenaire technique est aussi crucial que le choix technologique lui-même. Voici les critères que nous recommandons de vérifier lors des phases d’appel d’offres.
Questions techniques à poser
Ne vous contentez pas de regarder le portfolio visuel. Interrogez l’agence sur ses pratiques DevOps. Demandez : « Comment gérez-vous les montées de charge imprévues ? », « Avez-vous des procédures de tests automatisés ? », « Quelle est votre stratégie de sauvegarde et de reprise après sinistre (PRA) ? ». Une agence qui ne peut pas détailler sa méthodologie de déploiement continu ou qui ne mentionne pas la conteneurisation doit lever un drapeau rouge pour un projet d’envergure.
Signaux d’alerte
Méfiez-vous des agences qui proposent une solution propriétaire « maison » pour tout gérer. Cela crée un verrouillage technologique (Vendor Lock-in) dangereux pour la pérennité. De même, une agence qui accepte de démarrer le développement sans une phase préalable de conception d’architecture et de spécifications techniques démontre un manque de sérieux sur les enjeux de scalabilité.
Indicateurs de qualité
Privilégiez les agences qui peuvent démontrer une expertise sur les fournisseurs Cloud majeurs (certifications AWS, Azure, GCP). La présence de profils « Architecte Solution » ou « DevOps » identifiés dans l’équipe projet est un gage de compétence sur ces sujets structurels.
Tendances et évolutions du marché
Le paysage du développement web évolue rapidement, et les standards de scalabilité se transforment.
Serverless et Edge Computing
La tendance forte est à l’abstraction totale de l’infrastructure. Le « Serverless » permet d’exécuter du code uniquement à la demande, facturé à la milliseconde, offrant une scalabilité théoriquement infinie et un coût nul au repos. Parallèlement, l’Edge Computing pousse le traitement des données au plus près de l’utilisateur (sur les nœuds du CDN), réduisant drastiquement la latence mondiale.
Green IT et éco-conception
Nous observons une demande croissante pour des architectures sobres. La scalabilité ne doit plus se faire au prix d’une empreinte carbone désastreuse. L’optimisation du code et des ressources (éteindre les environnements de test la nuit, optimiser le poids des données) devient un critère de qualité technique et d’image de marque.
Coûts et TJM
L’expertise en architecture web et DevOps est en tension. Pour situer : le TJM moyen d’un développeur expérimenté s’établit entre 576 € (8-15 ans d’expérience) et 672 € (15 ans et plus) selon le baromètre Malt (relevé de juillet 2026), et les spécialistes architecture, cloud et DevOps se négocient au-dessus de ces moyennes. Bien que cela représente un coût initial plus élevé qu’un développeur full-stack junior, l’économie réalisée sur la maintenance et les coûts d’infrastructure à long terme est substantielle.
Ressource prête à l’emploi : Grille d’Audit de Maturité Technique
Pour vous aider à évaluer l’état actuel de votre projet ou à cadrer vos exigences futures, voici une grille de notation simplifiée que vous pouvez utiliser en interne ou transmettre à vos prestataires potentiels.
📥 Télécharger la grille d’audit au format Excel (gratuit, sans inscription) : les 7 domaines à noter de 1 à 3, une colonne d’actions, et le mode d’emploi pour en faire un filtre de sélection de prestataires.
| Domaine | Niveau Débutant (Risque Élevé) | Niveau Intermédiaire (Standard) | Niveau Avancé (Scalable & Pérenne) |
|---|---|---|---|
| Architecture | Monolithe « plat de spaghettis », code tout-en-un. | Monolithe structuré (MVC), séparation logique. | Monolithe modulaire ou Microservices, API-First. |
| Base de Données | Serveur unique, pas d’indexation suivie. | Réplication Maître/Esclave, sauvegardes auto. | Cluster haute dispo, Sharding, CQRS, NoSQL si besoin. |
| Cache | Pas de cache ou cache basique fichier. | Cache objet (Redis) pour sessions. | Stratégie complète : Varnish/CDN + Redis + Cache nav. |
| Hébergement | Serveur dédié unique ou mutualisé. | VPS avec load balancer simple. | Cloud (AWS/GCP), Auto-scaling groups, Kubernetes. |
| Déploiement | FTP manuel, modification directe en prod. | Script de déploiement, gestion de version (Git). | CI/CD complet, Tests auto, Blue/Green deployment. |
| Monitoring | On attend que le client signale le bug. | Ping serveur (Uptime), logs serveurs basiques. | APM (Datadog/NewRelic), Alerting proactif, Logs centralisés. |
| Sécurité | HTTPS basique. | Pare-feu serveur, backups réguliers. | WAF, Protection DDoS, Audits sécu réguliers (Pentests). |
FAQ : Questions fréquentes sur la scalabilité web
Quand faut-il passer d’une architecture monolithique aux microservices ?
C’est une question de seuil de complexité et non de trafic. Chez La Fabrique du Net, nous conseillons d’envisager les microservices lorsque vos équipes de développement deviennent trop grandes pour travailler sur la même base de code sans se marcher sur les pieds, ou lorsque des modules spécifiques nécessitent une scalabilité indépendante (ex: un module de traitement vidéo gourmand en CPU). Tant que votre équipe compte moins de 10-15 développeurs, un monolithe modulaire est souvent plus efficace et moins coûteux.
Quel est le coût réel d’une architecture Cloud scalable ?
Le modèle Cloud déplace les coûts du CAPEX (investissement matériel) vers l’OPEX (dépenses de fonctionnement). Si le ticket d’entrée est faible, la facture peut grimper vite si l’architecture n’est pas optimisée (instances orphelines, surdimensionnement). Pour un site e-commerce de taille moyenne (50k visiteurs/mois) avec une haute disponibilité, comptez un budget infrastructure mensuel de l’ordre de quelques centaines à 1 500 €, selon la redondance exigée. Pour des plateformes très sollicitées, cela peut aller de 5 000 € à plus de 20 000 € par mois. L’important est de rapporter ce coût au chiffre d’affaires sécurisé par la disponibilité du service.
Comment mesurer la dette technique d’un projet existant ?
La dette technique se mesure souvent indirectement : augmentation du temps nécessaire pour livrer une nouvelle fonctionnalité, hausse du nombre de bugs après chaque mise en production, ou réticence des développeurs à toucher certaines parties du code. Des outils d’analyse statique de code (comme SonarQube) peuvent donner des métriques chiffrées sur la complexité et la duplication du code, fournissant un indicateur objectif de la « santé » du projet.
Est-ce que le « Serverless » est adapté à tous les projets ?
Non. Le Serverless est excellent pour des tâches événementielles (traitement d’image après upload, API peu sollicitée, tâches planifiées). Cependant, pour des applications à trafic constant et élevé, ou nécessitant des connexions persistantes (WebSockets), les serveurs traditionnels ou conteneurs restent souvent plus performants et plus économiques. Il faut également prendre en compte le « Cold Start » (temps de démarrage à froid) qui peut introduire de la latence.
Quelle est la différence entre scalabilité verticale et horizontale ?
Imaginez que vous devez transporter plus de marchandises. La scalabilité verticale consiste à acheter un camion plus gros (plus de CPU/RAM). C’est simple mais limité par la taille maximale du plus gros camion disponible. La scalabilité horizontale consiste à acheter plusieurs petits camions (plus de serveurs). C’est une approche plus complexe à gérer (il faut coordonner la flotte), mais elle est théoriquement illimitée et plus résiliente (si un camion tombe en panne, les autres continuent).
Conclusion
La pérennisation et la scalabilité d’un site web ne sont pas le fruit du hasard, mais le résultat de choix architecturaux conscients et stratégiques. Du choix initial entre monolithe et microservices à la mise en place d’une culture DevOps rigoureuse, chaque décision pèse sur la capacité future de l’entreprise à grandir sans douleur. Ignorer ces aspects revient à construire un gratte-ciel sur des fondations de maison individuelle : l’effondrement est inévitable dès que l’on ajoute des étages.
Dans un écosystème digital où la performance est directement corrélée au chiffre d’affaires, s’entourer d’experts capables d’anticiper ces enjeux est vital. Les agences web généralistes ne disposent pas toujours de l’ingénierie nécessaire pour concevoir des systèmes à haute disponibilité. C’est ici que La Fabrique du Net intervient. Notre connaissance intime du marché des agences nous permet de vous orienter vers des partenaires techniques qui ne se contentent pas de coder, mais qui conçoivent des architectures durables, taillées pour accompagner votre ambition. N’attendez pas le crash serveur du prochain Black Friday pour repenser vos fondations.
Préparer votre site à monter en charge sans casse exige une vraie expertise technique : trouvez les agences de développement web capables de le faire évoluer sereinement.





![Créer une application web en 12 étapes [Guide]](https://cdn.lafabriquedunet.fr/27570/conversions/creer-une-application-web-en-12-etapes-guide-card.jpg)