On est en 2026. Si vous pensez encore que le SEO se résume à placer des mots-clés dans des balises H1 et à obtenir quelques backlinks, j’ai une mauvaise nouvelle pour vous : vous êtes resté bloqué dix ans en arrière. Aujourd’hui, le web a changé. Google n’est plus seulement un moteur de recherche, c’est un moteur de réponse alimenté par des intelligences artificielles voraces. Et devinez quelle est leur nourriture préférée ? Les données structurées.
La réponse courte : le balisage Schema.org décrit vos contenus dans un langage que les machines comprennent (une entreprise, un produit, une FAQ...), ce qui débloque les résultats enrichis de Google et aide les moteurs IA à vous citer correctement. Le format à utiliser en 2026 est le JSON-LD, un bloc de script à coller dans le <head>, sans toucher à votre HTML. Exemples copiables ci-dessous.
Je vois encore passer tellement de sites, même de grandes marques, qui négligent totalement cet aspect ou, pire, qui l’implémentent de manière automatique et bâclée via un plugin mal configuré. C’est un gâchis monumental. Le balisage sémantique n’est pas une option, c’est le vocabulaire que nous utilisons pour chuchoter à l’oreille des algorithmes. C’est la différence entre dire « je vends des chaussures » et dire « voici un objet de type Produit, de marque Nike, modèle Air Max, couleur rouge, en stock, à 120 euros, avec 45 avis positifs ».
Dans ce guide, on va oublier la théorie scolaire. Je vais vous partager ce que j’applique sur le terrain pour mes clients, comment je structure la donnée pour construire une autorité inébranlable et comment vous pouvez, vous aussi, transformer votre code HTML en une mine d’or pour les moteurs de recherche.
La réalité du SEO en 2026 : Parler la langue des Entités
Pour comprendre l’importance du schema balisage, il faut comprendre l’évolution de Google. Nous sommes passés du « Strings » (chaînes de caractères) au « Things » (choses/entités). Avant, Google cherchait le mot « avocat » sur une page. Aujourd’hui, il cherche à comprendre si vous parlez du fruit ou du métier juridique. C’est là que la sémantique entre en jeu.
Le balisage sémantique via le vocabulaire Schema.org permet de lever toute ambiguïté. En 2026, avec l’avènement de la SGE (Search Generative Experience) et des réponses directes par IA, votre contenu n’est souvent même plus visité s’il n’est pas compris instantanément. Les moteurs de recherche extraient les informations factuelles de vos pages pour construire leurs propres réponses. Si vous ne leur mâchez pas le travail avec des données structurées, ils iront voir chez votre concurrent qui, lui, l’a fait.
L’objectif n’est pas seulement d’avoir des étoiles dans les résultats de recherche (les fameux rich snippets), c’est de définir qui vous êtes, ce que vous faites et comment vous êtes connecté au reste du monde. C’est ce qu’on appelle le Knowledge Graph.
JSON-LD vs Microdonnées : Le débat est clos
Il y a quelques années, on se battait encore avec les microdonnées (microdata) intégrées directement dans le HTML. Vous savez, ces attributs itemscope et itemtype qu’on devait glisser péniblement dans les balises div ou span. C’était lourd, c’était difficile à maintenir, et ça cassait souvent le design.
Soyons clairs : en 2026, le standard absolu, c’est le JSON-LD (JavaScript Object Notation for Linked Data). C’est le format recommandé par Google. Pourquoi ? Parce qu’il dissocie la donnée de la présentation. Vous pouvez avoir votre code visuel d’un côté, et un script propre, net et précis dans le <head> ou le <body> de votre page qui contient toute la structure sémantique.
L’avantage du JSON-LD est sa flexibilité. Je peux injecter des données structurées dynamiquement via Google Tag Manager sans jamais toucher au code source du site, ou générer des scripts complexes côté serveur qui décrivent des relations entre plusieurs entités sans alourdir le DOM HTML visible par l’utilisateur. Si vous utilisez encore des microdonnées en ligne, il est temps de faire le ménage.
L’Architecture de la Connaissance : Comprendre le Knowledge Graph
C’est ici que la plupart des gens décrochent, mais c’est ici que les vrais pros du SEO gagnent. Le but du balisage schema n’est pas juste de décrire une page isolée. C’est de connecter les points.
Imaginez votre site comme une toile. Vous avez une page « À propos » qui décrit votre entreprise (Organization). Vous avez des articles de blog (BlogPosting) écrits par un auteur (Person). Vous avez des produits (Product) vendus par l’entreprise.
Une erreur classique est de mettre un bloc de schema « Article » sur une page de blog, et c’est tout. Le professionnel passionné, lui, va utiliser la propriété author pour lier l’article à l’entité « Person » de l’auteur, et la propriété publisher pour lier à l’entité « Organization ». En faisant cela, vous aidez Google à comprendre l’autorité de l’auteur et la légitimité de l’éditeur. Vous construisez votre E-E-A-T (Expérience, Expertise, Autorité, Fiabilité) directement dans le code.
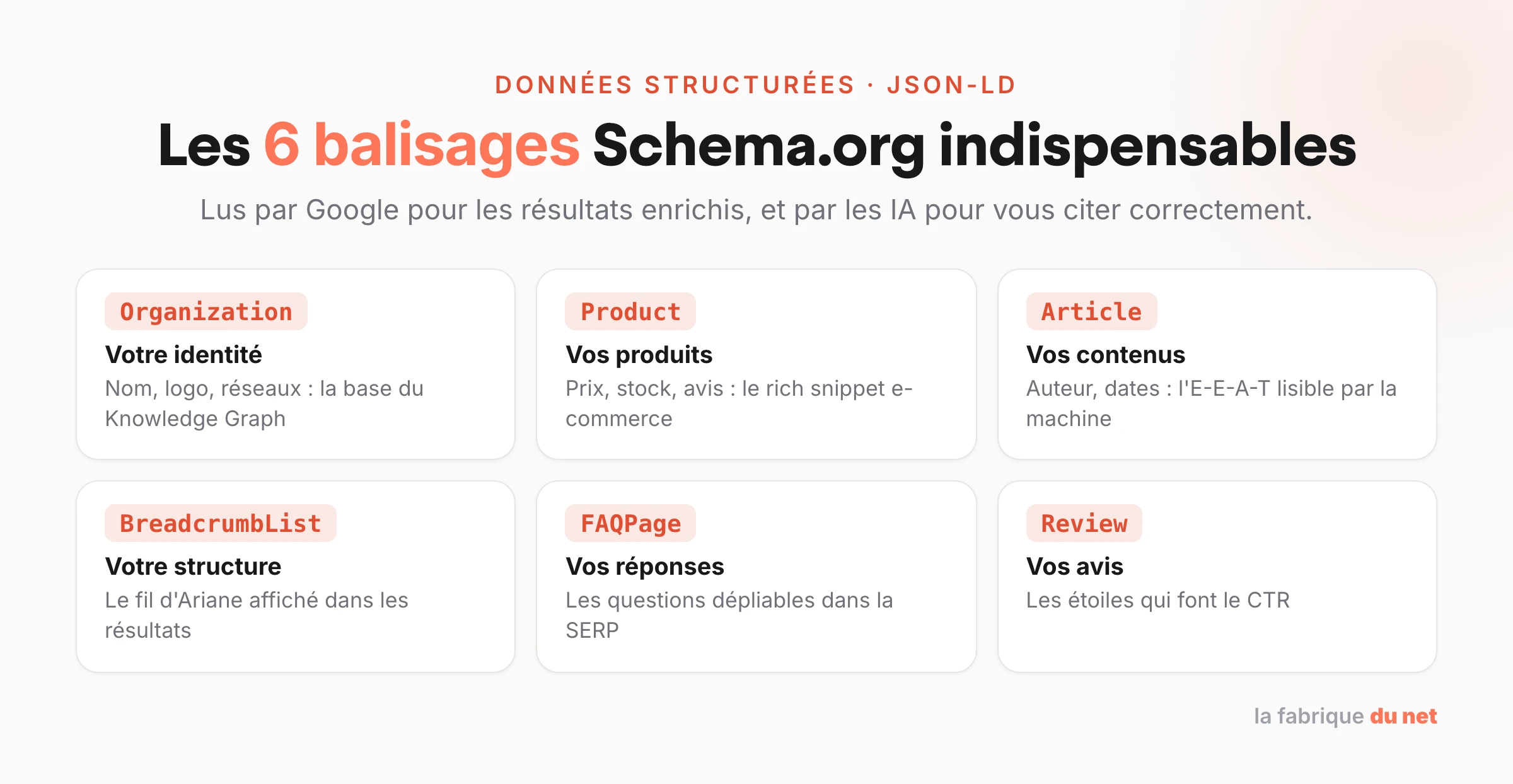
Les types de données structurées indispensables en 2026
Le vocabulaire Schema.org est immense, avec des centaines de types. Mais ne vous noyez pas. Voici les piliers que j’implémente systématiquement sur les sites performants.
Organization et LocalBusiness
C’est la base de la base. Sur votre page d’accueil ou votre page contact, vous devez dire à Google qui vous êtes. Si vous êtes une entreprise locale (plombier, restaurant, agence immo), le type LocalBusiness est vital. Il permet de définir vos horaires, votre zone de chalandise (areaServed), vos coordonnées GPS et votre adresse exacte.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Votre Entreprise",
"url": "https://votresite.fr",
"logo": "https://votresite.fr/logo.png",
"sameAs": [
"https://www.linkedin.com/company/votre-entreprise",
"https://www.instagram.com/votre-entreprise"
],
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+33-1-23-45-67-89",
"contactType": "customer service",
"availableLanguage": "French"
}
}
</script>
Pour une marque nationale ou un site pure-player, on utilisera Organization. N’oubliez jamais la propriété sameAs : c’est là que vous listez vos profils sociaux (Facebook, LinkedIn, X, Wikipedia). C’est ce qui permet à Google de consolider votre identité numérique.
Product et Merchant Listing
Si vous faites du e-commerce, le balisage Product est votre meilleur ami. En 2026, Google est devenu une marketplace géante. Vos produits peuvent apparaître dans l’onglet Shopping, dans les images, et dans les résultats enrichis avec le prix, la disponibilité et les avis.
Attention aux détails : il ne suffit pas de mettre le prix. Il faut gérer les variantes (tailles, couleurs) avec ProductGroup, gérer les codes GTIN/EAN (indispensables pour le rapprochement des produits), et surtout les offres (Offer) avec la disponibilité en temps réel. Une donnée priceValidUntil manquante peut parfois vous faire perdre l’affichage du prix dans les SERP.
Article et BlogPosting
Pour les éditeurs de contenu, c’est le standard. Cela permet à vos articles d’apparaître dans Google Discover et dans le carrousel « À la une ». La distinction entre Article (générique), NewsArticle (actualité chaude) et BlogPosting (billet de blog) est importante pour le ciblage.
Un conseil d’expert : utilisez la propriété speakable. Avec la montée en puissance des assistants vocaux et des lectures d’articles par IA, définir les parties de votre contenu qui sont propices à la synthèse vocale est un atout futuriste.
BreadcrumbList (Fil d’Ariane)
Souvent négligé, le fil d’Ariane structuré (BreadcrumbList) est pourtant crucial. Il aide les moteurs de recherche à comprendre la hiérarchie de votre site. Visuellement, cela remplace l’URL verte moche dans les résultats de recherche par un chemin de navigation propre (Accueil > Catégorie > Produit), ce qui améliore le taux de clic.
FAQPage et HowTo
Même si Google a réduit la visibilité des FAQ dans les résultats classiques pour éviter d’encombrer les pages, ces données restent de l’or pur pour nourrir les modèles de langage (LLM) de Google. Une page balisée avec HowTo (Tutoriel) ou FAQPage est structurée étape par étape, ce qui est le format idéal pour qu’une IA puisse extraire la réponse et vous citer comme source.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Votre question fréquente ?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Votre réponse, identique à celle affichée sur la page."
}
}]
}
</script>
Règle absolue : le balisage doit décrire un contenu réellement visible sur la page. Baliser des données invisibles est le chemin le plus court vers une action manuelle Google.
Review et AggregateRating
La preuve sociale est le moteur de la conversion. Le balisage AggregateRating permet d’afficher les fameuses étoiles jaunes. Attention cependant : Google est devenu très strict. Vous ne pouvez pas baliser des avis globaux sur la page d’accueil (self-serving reviews) pour une entreprise locale. Les avis doivent être liés à un produit spécifique ou un service précis. Tricher ici, c’est s’exposer à une action manuelle (pénalité) rapide.
La technique avancée : Le maillage d’entités (Nesting & @id)
Vous voulez passer au niveau supérieur ? Parlons de la syntaxe. La plupart des plugins génèrent des blocs JSON séparés. Un bloc pour le fil d’Ariane, un bloc pour l’article, un bloc pour l’auteur. C’est bien, mais c’est déconnecté.
La méthode pro consiste à utiliser l’attribut @id. C’est un identifiant unique pour une entité dans votre page (souvent l’URL suivie d’une ancre, comme #organization ou #author).
Imaginez le scénario :
- Je définis mon Organization avec l’ID
https://monsite.com/#organization. - Je définis mon Auteur avec l’ID
https://monsite.com/#hugo. - Dans mon schema Article, au lieu de réécrire toutes les infos de l’éditeur, je fais simplement référence à
{"@id": "https://monsite.com/#organization"}.
En faisant cela, vous créez un graphe de connaissances interconnecté sur votre propre page. Vous dites à Google : « Cet article a été écrit par CETTE personne précise, qui travaille pour CETTE organisation précise ». C’est extrêmement puissant pour consolider la confiance et l’autorité.
Implémentation concrète : Au-delà des plugins
Je sais, vous utilisez probablement WordPress et un plugin comme Yoast, RankMath ou SEOPress. Ces outils font un travail décent pour 80% des sites. Ils automatisent le balisage schema de base. Mais si vous lisez cet article, vous ne visez pas la moyenne.
Les limites des plugins sont vites atteintes dès que vous avez des besoins spécifiques : un catalogue produit complexe, des événements avec plusieurs dates, des offres d’emploi, ou des recettes de cuisine avec des valeurs nutritionnelles précises.
Voici comment je procède pour une implémentation sur mesure :
- Audit de l’existant : J’utilise l’outil de test resultats enrichis de Google pour voir ce qui est déjà généré par le thème ou les plugins. Souvent, on trouve des doublons ou des erreurs.
- Modélisation : Je rédige le JSON-LD idéal à la main ou avec des générateurs comme celui de Merkle, en intégrant toutes les propriétés recommandées et optionnelles. Plus on donne d’informations, mieux c’est.
- Intégration :
- Si je peux modifier le code (ou via un développeur), j’injecte le JSON dynamique dans le template PHP/JS.
- Si je n’ai pas accès au code, j’utilise Google Tag Manager. On peut créer une variable JavaScript personnalisée qui va « scrapper » les éléments de la page (titre, date, auteur, prix) pour remplir le JSON, et l’injecter via une balise HTML personnalisée. C’est une méthode redoutable pour les marketeurs agiles.
E-E-A-T et crédibilité : Le rôle caché du Schema
On parle beaucoup de l’E-E-A-T depuis quelques années. Google veut mettre en avant des contenus créés par des experts. Mais comment Google sait-il que vous êtes un expert ? Il ne lit pas votre CV papier.
Le balisage de données structurées est votre CV numérique. En utilisant le type Person, vous pouvez indiquer vos diplômes (alumniOf), vos récompenses (award), votre poste actuel (jobTitle) et vos autres publications. En liant ces données à vos articles, vous prouvez mathématiquement votre expertise aux algorithmes.
Pour les sites YMYL (Your Money Your Life – Santé, Finance), c’est absolument critique. Une page médicale revue par un médecin doit utiliser le schema MedicalWebPage avec la propriété reviewedBy pointant vers le profil du médecin. C’est souvent ce détail qui fait la différence entre une page classée en première position et une page reléguée en page 10.
Erreurs courantes et pénalités
Attention, le balisage sémantique n’est pas une zone de non-droit. Google a des guidelines strictes. Voici les erreurs que je vois trop souvent et qui peuvent vous coûter cher :
- Contenu invisible : Baliser des données qui ne sont pas visibles par l’utilisateur humain sur la page. Si vous dites dans le schema que le produit coûte 50€, mais que le prix n’est affiché nulle part sur la page, c’est du spam. C’est une violation directe des consignes (Cloaking de données structurées).
- Mauvaise catégorisation : Utiliser le schema
Recipepour quelque chose qui n’est pas une recette (comme une recette de « succès en affaires ») juste pour avoir une photo dans les SERP. - Avis inventés : Baliser des 5 étoiles alors qu’aucun système de collecte d’avis n’existe sur le site.
- Listes non ordonnées : Oublier d’utiliser
ItemListpour les pages de catégories, empêchant Google de comprendre la liste des produits présentés.
Utilisez toujours le Rich Results Test (Test des résultats enrichis) de Google et le Schema Markup Validator (l’outil officiel de Schema.org) pour valider votre code. Ne vous fiez pas à l’aperçu, vérifiez qu’il n’y a ni erreurs, ni avertissements critiques.
L’avenir du balisage : Vers le Web Sémantique total
Nous nous dirigeons vers un web où l’interface visuelle ne sera qu’une des nombreuses façons de consommer le contenu. Les agents IA personnels, les lunettes de réalité augmentée, les assistants vocaux domestiques… tous ces dispositifs se nourrissent de données brutes et structurées.
Investir aujourd’hui dans un balisage schema complet, précis et interconnecté, c’est préparer votre site pour les dix prochaines années. C’est transformer votre site web d’une simple brochure numérique en une base de données structurée accessible universellement.
Alors, ne vous contentez pas du minimum syndical. Ouvrez le capot de votre site, plongez dans le JSON-LD, et commencez à structurer votre réalité pour que Google puisse la comprendre dans toute sa nuance. C’est ça, le travail d’un vrai professionnel du SEO en 2026.
Si vous avez des doutes sur votre implémentation ou si vous voulez aller plus loin, n’hésitez pas à tester vos pages dès maintenant. Le web sémantique n’attend pas.
Schema.org et les moteurs IA : le nouveau front
En 2026, votre balisage ne parle plus seulement à Google : ChatGPT, Perplexity et les AI Overviews s'appuient sur les données structurées pour identifier qui vous êtes, ce que vous vendez et à quel prix. Un site correctement balisé (Organization avec sameAs, Product avec prix à jour, FAQPage propre) a mécaniquement plus de chances d'être cité correctement par les assistants IA qu'un site que la machine doit deviner. C'est le même chantier que le SEO classique, avec un enjeu de plus : la fiabilité des entités. Vérifiez que votre nom, votre adresse et vos liens sociaux sont identiques partout, balisage compris.
Pour valider votre implémentation, deux outils : le test des résultats enrichis de Google et le validateur Schema.org. Et si vous préférez déléguer, le balisage fait partie du socle technique que traitent les agences SEO.


