L’intelligence artificielle est devenue, en l’espace de quelques années, le nouveau levier de croissance incontournable pour les entreprises françaises. Les briefs déposés sur notre plateforme le montrent : les demandes de projets intégrant des briques d’IA explosent, que ce soit pour de la maintenance prédictive, de la personnalisation client ou de l’automatisation de processus. Cependant, un constat alarmant remonte quasi systématiquement de nos échanges avec les porteurs de projets et les agences expertes : la majorité de ces initiatives peinent à atteindre leurs objectifs, non pas à cause des algorithmes, mais à cause de la matière première qu’ils ingèrent, à savoir la donnée. « Garbage in, garbage out » (déchets en entrée, déchets en sortie) reste l’adage le plus pertinent du secteur. Une IA, aussi sophistiquée soit-elle, ne peut produire de résultats fiables si elle est entraînée sur des données incomplètes, obsolètes ou biaisées.
Trop d’entreprises investissent massivement dans des solutions de Data Science avant même d’avoir audité leur patrimoine de données. C’est une erreur stratégique coûteuse. La performance d’une IA dépend avant tout de la structuration, du nettoyage et de la gouvernance des données sources. Cet article a pour vocation de déconstruire le mythe de l’IA magique et de remettre l’accent sur le travail fondamental de l’ingénierie des données. Nous allons explorer ensemble, avec le prisme de notre expérience terrain, comment transformer vos bases de données en un actif stratégique capable de propulser véritablement vos ambitions en intelligence artificielle.
La gouvernance des données : fondation indispensable de toute stratégie IA
Avant même de parler de nettoyage technique ou d’algorithmes, il est impératif d’aborder la question de la gouvernance. Gartner estimait ainsi qu’au moins 30 % des projets d’IA générative seraient abandonnés après leur preuve de concept d’ici fin 2025, la mauvaise qualité des données figurant en tête des causes citées ; et sur le terrain, l’absence de gouvernance claire est la cause racine la plus fréquente des échecs en phase de mise en production. La gouvernance des données ne se résume pas à une série de documents administratifs ; c’est un ensemble de processus, de rôles et de responsabilités qui garantissent que la donnée est fiable, sécurisée et accessible. Sans ce cadre, l’IA risque d’amplifier les incohérences organisationnelles existantes.
Concrètement, une bonne gouvernance commence par la désignation de propriétaires de la donnée (Data Owners) au sein des directions métiers. Ce ne sont pas les équipes IT qui doivent porter la responsabilité de la définition d’un « client actif » ou d’une « marge brute », mais bien les départements Vente ou Finance. Nous recommandons fortement de cartographier les flux de données pour comprendre leur cycle de vie, de la création à l’archivage. Pour une entreprise qui souhaite déployer de l’IA, cela signifie être capable de tracer l’origine de chaque donnée qui alimente le modèle (Data Lineage). Si votre algorithme de pricing prend une décision erronée, vous devez pouvoir remonter la chaîne pour identifier si l’erreur vient du modèle ou d’une donnée erronée saisie dans l’ERP trois jours plus tôt.
En termes de maturité, les entreprises qui réussissent leurs projets IA ont souvent mis en place un dictionnaire de données partagé. Cela évite les ambiguïtés sémantiques qui polluent les modèles. Par exemple, le terme « chiffre d’affaires » peut avoir trois définitions différentes entre le marketing, la comptabilité et les ventes. Une IA entraînée sur un mélange de ces définitions produira des prédictions inutilisables. La gouvernance sert à normaliser ces définitions en amont.
Le nettoyage des bases de données legacy : un défi technique et humain
Le principal frein technique concerne la gestion des systèmes hérités, ou « legacy ». De nombreuses PME et ETI françaises fonctionnent avec des historiques de données s’étalant sur 15 ou 20 ans, stockés dans des systèmes cloisonnés (silos). Ces bases de données historiques sont souvent truffées de doublons, de champs vides, de formats hétérogènes et d’informations obsolètes. Vouloir brancher une IA moderne sur ce type d’architecture sans phase de nettoyage est une utopie.
Le nettoyage de données (Data Cleaning) représente souvent 70 % à 80 % du temps d’un projet de Data Science. C’est une réalité que les décideurs ont parfois du mal à accepter, car c’est une phase moins « glamour » que la modélisation prédictive, mais elle est critique. Les techniques modernes impliquent l’utilisation d’outils d’ETL (Extract, Transform, Load) ou d’ELT performants capables de standardiser les formats. Par exemple, uniformiser les formats de dates, corriger les fautes de frappe dans les noms de villes, ou encore normaliser les devises. Mais au-delà de la syntaxe, c’est la cohérence métier qui doit être vérifiée.
Un aspect souvent sous-estimé est la gestion des valeurs manquantes. Deux approches coexistent : la suppression des lignes incomplètes ou l’imputation (remplacement des valeurs manquantes par une moyenne ou une médiane). Le choix entre ces deux méthodes a un impact drastique sur le comportement de l’IA. Supprimer trop de données réduit la représentativité de l’échantillon, tandis qu’une imputation mal faite introduit un biais artificiel. C’est ici que l’expertise d’une agence spécialisée en Big Data & BI prend tout son sens, pour conseiller la meilleure stratégie de redressement des données sans dénaturer la réalité statistique.
L’impact direct de la qualité des données (« Data Quality ») sur le ROI de l’IA
Deux affaires publiques donnent l’échelle des enjeux. En 2022, Unity a annoncé environ 110 millions de dollars d’impact sur son chiffre d’affaires après que son outil publicitaire Audience Pinpointer a ingéré les données corrompues d’un gros client : un seul flux pollué a dégradé les modèles de ciblage, et l’action a perdu 37 % en une séance. Un an plus tôt, Zillow fermait son activité d’achat-revente immobilier : son algorithme de valorisation, nourri de données qui ne reflétaient plus un marché en bascule, avait fait surpayer des milliers de maisons, pour plus de 500 millions de dollars de pertes et 25 % des effectifs licenciés. Dans les deux cas, le modèle fonctionnait ; ce sont les données qui ont menti.
Il existe une corrélation directe et mesurable entre la qualité des données (Data Quality) et le Retour sur Investissement (ROI) des projets d’intelligence artificielle. Les entreprises qui investissent d’emblée une part significative de leur budget dans l’audit et le nettoyage des données atteignent leur seuil de rentabilité bien plus vite que celles qui négligent cette étape. La raison est simple : une IA entraînée sur des données propres nécessite moins de cycles de ré-entraînement et produit de la valeur plus rapidement.
Prenons le cas des dimensions de la qualité des données. Pour qu’une IA soit performante, la donnée doit respecter plusieurs critères : l’exactitude (la donnée reflète-t-elle la réalité ?), la complétude (manque-t-il des informations cruciales ?), la cohérence (les données sont-elles logiques entre elles ?) et la fraîcheur (les données sont-elles à jour ?). Si l’un de ces piliers s’effondre, le ROI chute. Par exemple, dans le secteur du retail, une IA de recommandation de produits qui se base sur un historique d’achat vieux de cinq ans sans prendre en compte les retours produits récents va recommander des articles que le client n’aime plus ou qui ne sont plus en stock. Le résultat est une expérience client dégradée et des ventes perdues, là où l’IA était censée générer du chiffre d’affaires additionnel.
L’impact se mesure aussi en termes de maintenance. Un modèle d’IA n’est pas statique ; il doit évoluer. Si les données d’alimentation sont de mauvaise qualité, la dérive du modèle (Model Drift) sera rapide et difficile à détecter. Les équipes techniques passeront alors leur temps à essayer de comprendre pourquoi les prédictions se dégradent, au lieu de développer de nouvelles fonctionnalités. C’est un coût caché opérationnel (OPEX) qui peut devenir colossal sur le long terme. Investir dans la qualité des données est donc une mesure de protection de l’investissement initial (CAPEX).
Structuration des données non structurées : le nouvel eldorado
Une grande partie de la valeur potentielle de l’IA réside aujourd’hui dans l’exploitation des données non structurées : images, vidéos, fichiers PDF, emails, conversations de chatbots. Contrairement aux données tabulaires classiques (lignes et colonnes), ces informations sont par nature désorganisées. Pourtant, elles contiennent souvent la « voix du client » ou des détails techniques cruciaux. La demande croît pour des projets visant à structurer ces amas d’informations pour nourrir des modèles de NLP (Traitement du Langage Naturel) ou de Computer Vision.
Le défi ici est double : l’extraction et l’annotation. Pour qu’une IA puisse apprendre à partir de factures scannées par exemple, il ne suffit pas de faire de l’OCR (reconnaissance de caractères). Il faut structurer l’information : identifier que tel montant correspond à la TVA, tel autre au total HT, et lier ces informations à une fiche fournisseur dans l’ERP. C’est un travail d’ingénierie de la donnée complexe. Les agences spécialisées utilisent de plus en plus des architectures de type « Data Lakehouse » qui permettent de stocker ces données brutes tout en offrant une couche de structuration pour l’analyse.
L’annotation des données (Data Labeling) est également un goulot d’étranglement majeur. Pour qu’une IA reconnaisse un défaut sur une pièce industrielle, il faut lui montrer des milliers d’exemples de pièces défectueuses et saines, correctement étiquetés par des humains experts. La qualité de cet étiquetage est primordiale. Si 10 % des étiquettes sont fausses, le modèle ne convergera jamais vers une précision acceptable. La structuration des données passe donc aussi par la mise en place de processus de validation humaine rigoureux (Human-in-the-loop).
L’importance de l’architecture Data : du Data Warehouse au Data Mesh
La qualité des données est intrinsèquement liée à l’architecture qui les supporte. Historiquement, les entreprises centralisaient tout dans un Data Warehouse monolithique. Si cette approche a le mérite de la cohérence, elle manque souvent d’agilité pour les besoins modernes de l’IA qui requièrent des volumes massifs et une grande vélocité. Aujourd’hui émergent des architectures plus flexibles qui favorisent une meilleure qualité par la responsabilisation.
Le concept de Data Mesh, par exemple, gagne du terrain dans les grandes organisations. L’idée est de décentraliser la propriété de la donnée par domaine métier, tout en gardant une gouvernance fédérée. Chaque domaine (ex: Logistique, Marketing) est responsable de la qualité de ses « produits de données » qu’il met à disposition des autres. Cela résout le problème du goulot d’étranglement de l’équipe Data centrale qui ne maîtrise pas les subtilités métier de toutes les données qu’elle nettoie. En rapprochant la gestion de la qualité de la source de création de la donnée, on améliore mécaniquement la pertinence des datasets fournis aux algorithmes d’IA.
Pour les PME, sans aller jusqu’au Data Mesh complet, l’adoption d’architectures cloud modernes (comme Snowflake, Google BigQuery ou Databricks) permet de séparer le stockage du calcul et de faciliter les pipelines de nettoyage automatisés. Ces outils offrent des fonctionnalités natives pour surveiller la qualité des données et alerter en cas d’anomalie avant même que la donnée n’atteigne le modèle d’IA. C’est ce qu’on appelle l’observabilité des données (Data Observability), une tendance lourde qui transforme la maintenance réactive en pilotage proactif.
Scénario type : le moteur de recommandation qui proposait des pièces de camion pour une citadine
Pour illustrer concrètement l’impact du nettoyage de données, voici un scénario type, représentatif des distributeurs à catalogue profond. Les détails sont illustratifs.
Un distributeur de pièces détachées automobiles veut un moteur de recommandation IA pour son portail B2B : plus de 2 millions de références accumulées en 15 ans, au fil de rachats de concurrents et d’imports fournisseurs hétérogènes. Le projet lancé en interne échoue : les recommandations sont aberrantes (des plaquettes de frein de camion proposées pour une citadine), simplement parce que des attributs techniques sont mal renseignés ou décalés d’une colonne. Le budget initial est consommé sans résultat.
L’approche type d’une agence Big Data : commencer par l’audit, puis une phase de « Data Remediation » de plusieurs mois (déduplication, normalisation des attributs, règles de validation par famille de produits) avant de rebrancher l’algorithme sur la base assainie. Le mécanisme à retenir : le moteur de recommandation n’était pas mauvais, il était fidèle à des données fausses, et la majorité du budget utile est partie dans la donnée, pas dans le modèle.
Et en vrai ? Sur les 68 missions data et BI publiées avec leur budget par les agences référencées sur notre plateforme, la médiane s’établit à 10 000 €, la moitié des missions entre 4 000 € et 60 000 € (relevé de juillet 2026) : l’amplitude reflète exactement l’écart entre un audit ciblé et une remédiation complète.
Les erreurs les plus fréquentes
Notre position d’intermédiaire nous permet de lister les écueils récurrents qui mènent les projets IA à l’échec ou au dépassement budgétaire. Voici les erreurs les plus fréquentes concernant la qualité des données.
Sous-estimer la phase de préparation des données
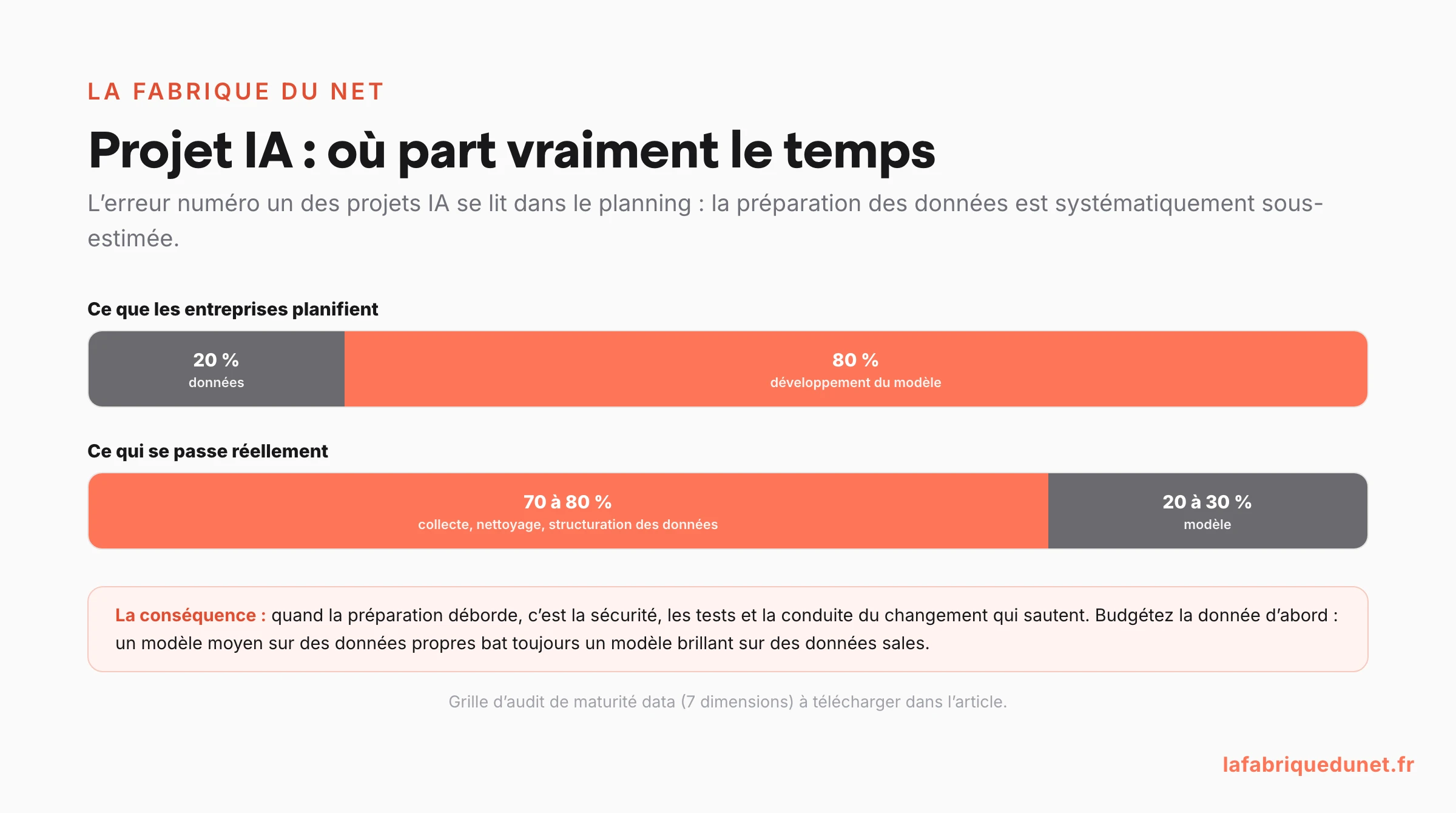
C’est l’erreur classique numéro un. Les entreprises planifient souvent 80 % du temps pour le développement du modèle et 20 % pour les données. La réalité est inverse. Vouloir raccourcir la phase de préparation conduit invariablement à des retards plus tard, car il faut « débugger » le modèle qui réagit mal à des données imprévues. Une bonne règle empirique est de considérer que la donnée ne sera jamais propre par défaut et qu’elle nécessitera toujours un travail substantiel.
Ignorer le contexte métier de la donnée
Confier le nettoyage des données uniquement à des profils techniques (Data Engineers) sans impliquer les experts métier est dangereux. Un ingénieur peut voir une valeur « 0 » dans une colonne « Prix » et décider de la supprimer ou de la remplacer par la moyenne, pensant que c’est une erreur. Or, pour le métier, « 0 » peut signifier « Produit offert en promotion » ou « Échantillon ». Si ce contexte n’est pas capturé, le nettoyage détruit de l’information précieuse et fausse l’apprentissage de l’IA.
Traiter le nettoyage comme une action ponctuelle (One-shot)
Beaucoup d’entreprises nettoient leur base pour le lancement du projet (le « Run ») et pensent que c’est terminé. Or, les données continuent d’entrer chaque jour, potentiellement avec les mêmes erreurs si les processus de saisie n’ont pas changé. La qualité des données est un processus continu, pas un projet avec une date de fin. Sans pipelines automatisés de contrôle qualité en continu, la base se dégradera à nouveau en quelques mois (phénomène d’entropie des données).
Comment bien choisir son agence pour la Data Quality & BI
Choisir le bon partenaire pour structurer vos données est une décision critique. Sur notre plateforme, les compétences des agences sont documentées et vérifiables. Voici ce que vous devez rechercher et les questions à poser pour évaluer leur expertise réelle.
La première chose à vérifier est la méthodologie. Une agence sérieuse ne vous parlera pas tout de suite d’outils, mais de compréhension de vos processus. Demandez-leur : « Comment allez-vous gérer les cas limites et les incohérences métier ? » Si la réponse est uniquement technique (« nous utilisons tel script Python »), c’est un signal d’alerte. Une bonne réponse doit inclure des ateliers avec vos équipes métier pour définir les règles de gestion.
Interrogez-les sur leur stack technologique et leur capacité à s’adapter à la vôtre. Sont-ils agnostiques ou revendeurs d’une solution précise ? Une agence experte doit maîtriser les outils modernes de l’écosystème Data (dbt, Talend, Matillion, ou les services natifs Cloud AWS/Azure/GCP). Demandez également des exemples de livrables : à quoi ressemblera le rapport de qualité des données ? Aurez-vous accès à un tableau de bord de surveillance de la qualité (Data Quality Dashboard) ?
Enfin, méfiez-vous des promesses de « nettoyage automatique à 100 % grâce à l’IA ». Si l’IA aide au nettoyage, la validation humaine reste indispensable pour les données critiques. Un bon partenaire doit être transparent sur le taux d’automatisation possible et la charge de travail qui restera de votre côté pour valider les arbitrages complexes. Cherchez des partenaires qui parlent de « Data Ops » et d’industrialisation, signe qu’ils pensent à la pérennité de la solution.
Cette industrialisation de la qualité s’outille : des frameworks open source comme Great Expectations permettent de déclarer des tests automatiques sur les données (« cette colonne ne doit jamais contenir de NULL », « ce montant reste entre 0 et 10 000 ») exécutés à chaque mise à jour, exactement comme des tests unitaires en développement logiciel. Le nettoyage cesse d’être ponctuel pour devenir un contrôle continu.
Tendances et évolutions du marché
Le marché de la Data Quality et de la BI évolue très vite, poussé par les exigences de l’IA générative. Les briefs déposés sur notre plateforme racontent une mutation des demandes. Il y a encore deux ans, les clients cherchaient surtout à construire des tableaux de bord descriptifs. Aujourd’hui, la demande glisse vers la mise en place de « Data Platforms » robustes prêtes pour l’IA.
Une tendance forte est l’émergence des « Synthetic Data » (données synthétiques). Face aux contraintes du RGPD et à la rareté de certaines données réelles, les entreprises commencent à utiliser des algorithmes pour générer des données fictives mais statistiquement réalistes pour entraîner leurs modèles. Cela demande une maîtrise parfaite de la structure des données d’origine pour pouvoir les imiter sans les copier. Les agences en pointe commencent à proposer ce type de service pour accélérer les phases de test.
Sur le plan tarifaire, le marché se polarise. Les prestations de « nettoyage manuel » ou de saisie offshore voient leurs prix baisser, tandis que l’expertise en « Data Engineering » et architecture de données voit ses tarifs augmenter (TJM souvent compris entre 600 € et 1 200 € pour des profils seniors). Les entreprises comprennent que payer pour une architecture solide est plus rentable que de payer pour du nettoyage récurrent inefficace. L’automatisation via des outils « Low-code / No-code » pour la préparation des données permet aussi de redonner la main aux métiers, réduisant la dépendance aux équipes IT centrales.
Ressource prête à l’emploi : Grille d’Audit de Maturité Data
Téléchargez la grille d’audit de maturité data en Excel (7 dimensions notées sur 5, total et verdict automatiques, à faire remplir séparément par la DSI et un métier), ou parcourez le tableau ci-dessous.
Pour vous aider à évaluer si vos données sont prêtes pour un projet d’IA, nous avons élaboré cette grille d’audit simplifiée. Vous pouvez l’utiliser en interne pour faire un premier état des lieux avant de contacter une agence. Attribuez une note de 1 à 5 pour chaque critère.
| Dimension | Critère d’évaluation | Score 1 (Critique) | Score 5 (Excellent) |
|---|---|---|---|
| Accessibilité | Facilité d’accès aux données sources | Données en silos, accès manuel complexe, pas d’API. | Données centralisées (Cloud/Lake), API documentées, accès temps réel. |
| Complétude | Présence des champs obligatoires | Plus de 30% de valeurs manquantes sur les champs clés. | Moins de 1% de valeurs manquantes, gestion claire des NULLs. |
| Unicité | Présence de doublons | Nombreux doublons non identifiés (clients, produits). | Règles de déduplication actives, identifiant unique fiable (Golden ID). |
| Standardisation | Formats et normes | Formats hétérogènes (dates, devises, unités variées). | Formats standardisés ISO, nomenclatures unifiées. |
| Documentation | Connaissance de la donnée | Aucune documentation, connaissance tribale (dans la tête des gens). | Dictionnaire de données à jour, Data Catalog accessible à tous. |
| Gouvernance | Responsabilité et processus | Aucun propriétaire identifié, pas de processus de validation. | Data Owners nommés, processus de qualité automatisés et monitorés. |
| Historique | Profondeur des données | Historique < 6 mois ou archivé sur supports inaccessibles. | Historique > 3 ans accessible, permettant d’analyser la saisonnalité. |
Interprétation : Si votre score total est inférieur à 20, un projet de structuration des données est indispensable avant tout investissement en IA. Entre 20 et 28, des actions correctives ciblées sont nécessaires. Au-delà de 28, vous disposez d’une base solide pour lancer des POC (Proof of Concept) en IA.
FAQ : Vos questions sur la Data Quality et l’IA
Pourquoi la qualité des données est-elle cruciale pour l’IA ?
L’IA apprend par l’exemple. Si les exemples fournis (les données) sont erronés, le modèle apprendra des règles fausses. C’est le principe du « Garbage In, Garbage Out ». Une mauvaise qualité de données entraîne des prédictions biaisées, une perte de confiance des utilisateurs et peut même avoir des conséquences légales ou éthiques graves (discrimination algorithmique due à des biais dans les données historiques).
Combien coûte un audit de qualité des données ?
Le coût est très variable selon la volumétrie et la complexité de votre système d’information. Pour une PME avec quelques sources de données (ERP, CRM, Site Web), un audit sérieux réalisé par une agence spécialisée se situe généralement entre 5 000 € et 15 000 €. Pour des environnements complexes d’ETI ou de grands comptes, cela peut aller de 20 000 € à plus de 50 000 €. C’est un investissement qui permet souvent d’éviter de perdre des sommes bien plus importantes dans un projet IA voué à l’échec.
Quelle est la différence entre Data Cleaning et Data Governance ?
Le Data Cleaning (nettoyage) est l’action technique et opérationnelle de corriger les données (supprimer les doublons, corriger les formats). La Data Governance (gouvernance) est le cadre stratégique et organisationnel qui définit les règles, les rôles et les politiques pour empêcher que les données ne se salissent à l’avenir. Le nettoyage est le remède, la gouvernance est l’hygiène de vie préventive.
L’IA peut-elle nettoyer mes données à ma place ?
Oui et non. Il existe des outils basés sur le Machine Learning qui peuvent détecter des anomalies, suggérer des corrections (ex: regrouper « IBM » et « I.B.M. Inc. ») ou imputer des valeurs manquantes. Cependant, l’IA ne peut pas deviner le contexte métier ni prendre des décisions stratégiques sur la définition d’une donnée. L’humain reste indispensable pour valider les règles et arbitrer les cas ambigus. L’IA est un assistant puissant pour le Data Steward, pas un remplaçant.
Combien de temps faut-il pour nettoyer une base de données legacy ?
C’est rarement une affaire de quelques jours. Pour une migration ou un nettoyage complet d’une base legacy significative, comptez couramment entre 3 et 6 mois de travail. Cela inclut l’audit, la définition des règles de gestion avec les métiers, le développement des scripts de nettoyage, les tests et la validation. Sous-estimer ce délai est une cause fréquente de dérapage de planning.
Conclusion
L’engouement pour l’intelligence artificielle est légitime, tant les gains de productivité et d’innovation promis sont importants. Cependant, considérer l’IA comme une solution « plug-and-play » qui s’affranchit de la réalité de vos systèmes d’information est une illusion. Comme nous l’avons exploré tout au long de cet article, la qualité des données n’est pas une option technique, c’est le carburant même du moteur IA. Sans une donnée propre, structurée, documentée et gouvernée, les algorithmes les plus puissants resteront inopérants, voire contre-productifs.
Investir dans la Data Quality et la Business Intelligence, c’est construire les fondations solides de votre future entreprise « Data-Driven ». C’est un travail de l’ombre, exigeant et rigoureux, mais c’est celui qui garantit le ROI sur le long terme. Ne brûlez pas les étapes. Commencez par auditer votre patrimoine de données, assainissez vos bases historiques et mettez en place une gouvernance claire.
Trouver le bon partenaire pour mener ce chantier structurant est complexe. Le marché est vaste, les expertises sont variées et les promesses parfois trompeuses. C’est tout l’objet de notre plateforme : chaque agence Big Data et BI y est documentée par ses réalisations publiées, ses avis vérifiés et ses tarifs. Si vous souhaitez être accompagné pour structurer vos données avant de lancer votre projet IA, nous pouvons vous mettre en relation avec des experts qualifiés, adaptés à votre taille d’entreprise et à votre secteur d’activité, pour transformer vos données brutes en véritable levier de performance.
Fiabiliser vos données pour entraîner l’IA demande l’appui d’une agence experte en big data et BI, capable de structurer vos flux : 476 agences sont positionnées sur le Big Data et la BI parmi les 10 951 référencées sur notre plateforme (relevé de juillet 2026), et vous pouvez déposer votre projet gratuitement pour recevoir plusieurs devis sur la même base.
Pour prolonger : notre analyse de l’intégration de l’IA en entreprise (la suite logique une fois les données prêtes) et celle d’IA générative et confidentialité des données.